Amnezia GPT
Об Amnezia GPT
Amnezia GPT — это бот в Telegram для пользователей Amnezia Premium, который даёт доступ к AI-сервисам с повышенным уровнем приватности.
Подробнее о том, как обрабатываются данные в Amnezia GPT: Параметры моделей: Приватность.
Использование бота ограничено лимитом токенов.
Токены — это внутренняя «валюта» бота, которая расходуется на обработку запроса пользователя и генерацию ответа моделью.
Каждому пользователю Amnezia Premium доступен лимит в 80 000 токенов, который полностью обновляется 3 раза в день — каждые 8 часов.
Amnezia GPT помогает быстро находить и перепроверять информацию, разбираться в сложных темах, переводить и резюмироват�ь тексты, а также решать прикладные задачи и работать с изображениями.
В Amnezia GPT доступно несколько AI-моделей, таких как Gemini, GPT и Kimi. Все они:
- умеют пользоваться веб-поиском, а также генерировать и редактировать изображения, если вы не отключите эти инструменты в настройках
- умеют работать с изображениями, чтобы использовать их для контекста или объяснять, что на них изображено
От выбора модели зависит:
- стоимость обработки запроса (расход токенов)
- качество и «глубина» ответа
- скорость работы
- максимальная длина контекста (сколько переписки и текста модель способна учитывать)
- регион обработки запросов
- параметры приватности
Примеры сценариев использования:
- объяснение сложных тем простыми словами или, наоборот, на «профессиональном» уровне
- краткие выжимки: статьи, документы, длинные переписки, тезисы
- пе�ревод текста с сохранением смысла и тона
- написание и редактирование текста: письма, инструкции, посты, планы, чек-листы
- помощь с идеями и структурой: сценарии, варианты, сравнения, аргументы «за/против»
- работа с изображениями: создание, редактирование, а также распознавание
Подробнее об Amnezia GPT:
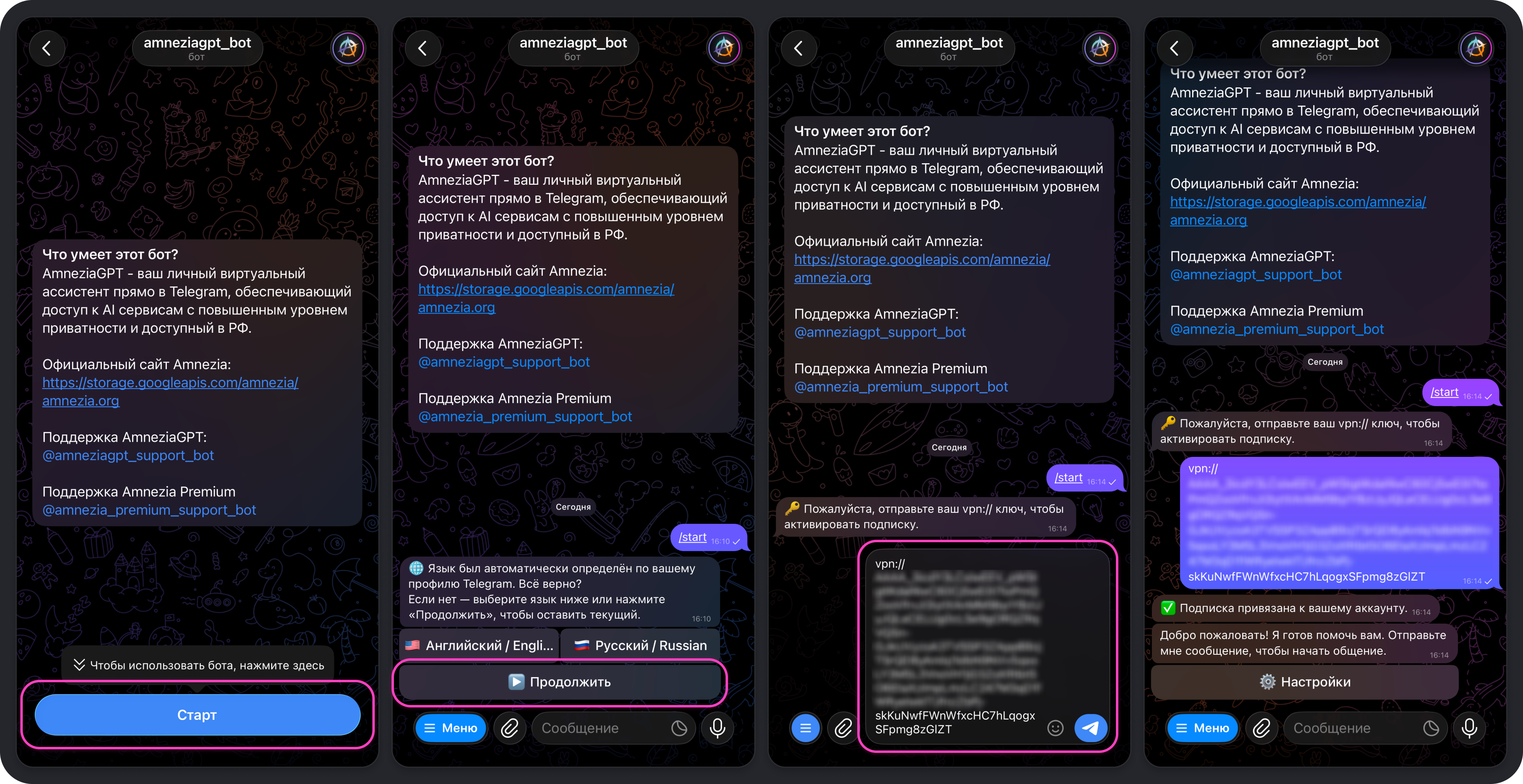
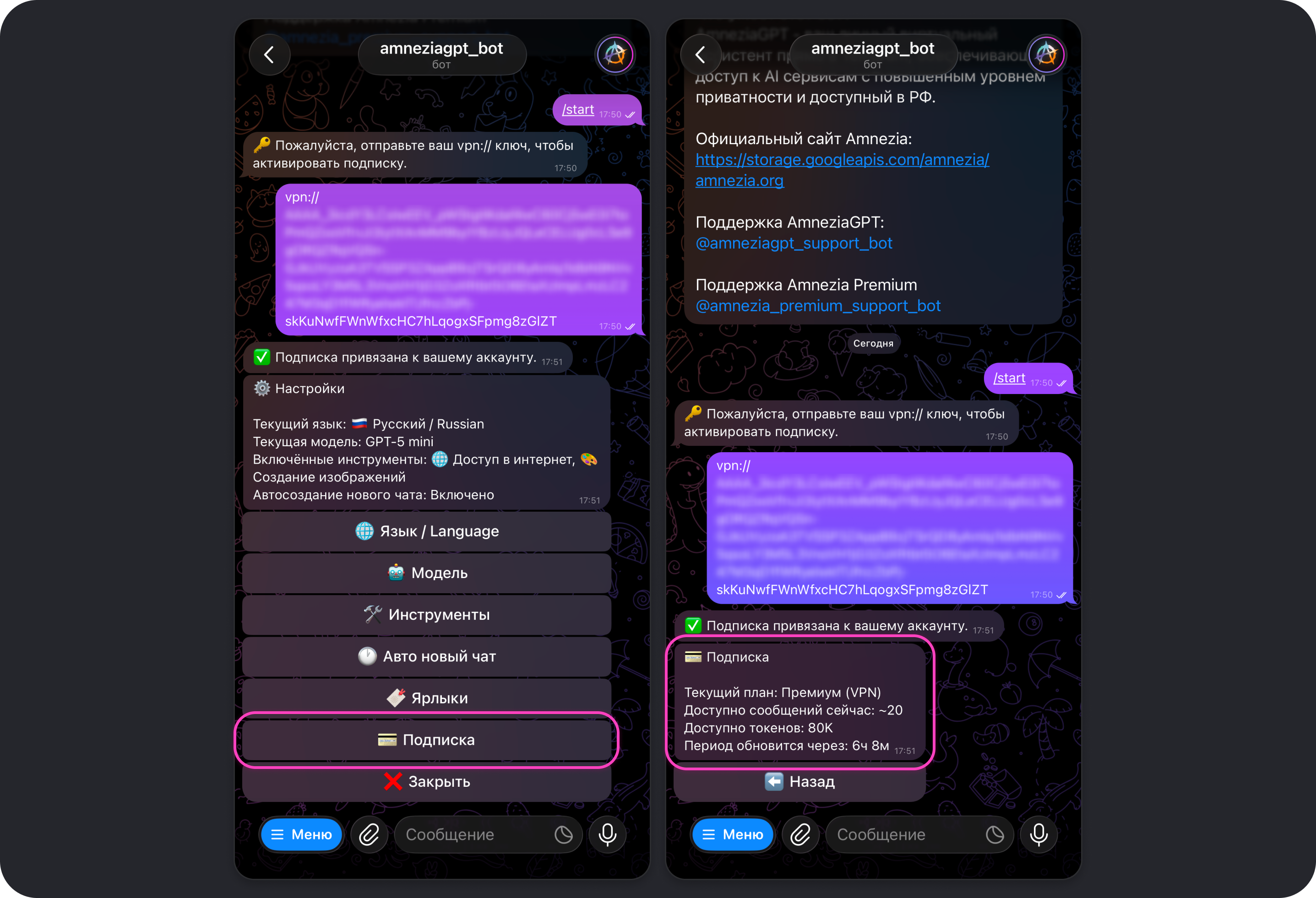
Как начать пользоваться Amnezia GPT
Для использования Amnezia GPT требуется наличие активной подписки Amnezia Premium и аккаунт в Telegram — именно там сейчас доступен бот Amnezia GPT.
Если у вас ещё нет подписки Amnezia Premium, вы можете приобрести её на официальном сайте Amnezia (зеркало).
Если у вас уже есть активная подписка Amnezia Premium:
- Перейдите в Telegram-бот и нажмите кнопку Старт.
- Выберите язык, на котором будет отображаться интерфейс взаимодействия с ботом.
- Отправьте в чат с ботом ваш ключ для подключения
vpn://....
После этого вы увидите сообщение об успешной привязке подписки к вашему Telegram-аккаунту, и можно сразу начать отправлять запросы в бота — их обработает модель, выбранная по умолчанию.
Мы рекомендуем ознакомиться с настройками бота, чтобы контролировать расход токенов: Настройки Telegram-бота Amnezia GPT.
При необходимости ключ подписки Amnezia Premium можно использовать в нескольких Telegram-аккаунтах. Доступный лимит (80 000 токенов) при этом не увеличивается — он остаётся общим и обновляется 3 раза в день (каждые 8 часов).
При необходимости ключ подписки можно отвязать в боте командой /logout.
Настройки Telegram-бота Amnezia GPT
Для перехода в настройки Amnezia GPT нажмите кнопку Настройки, отправьте в чат с ботом команду /settings или выберите эту команду из меню команд, которое отобразится при нажатии на кнопку Меню.
Пока меню настроек открыто, общение с ботом недоступно. Чтобы вернуться к взаимодействию с ботом, нажмите кнопку Закрыть в меню настроек.
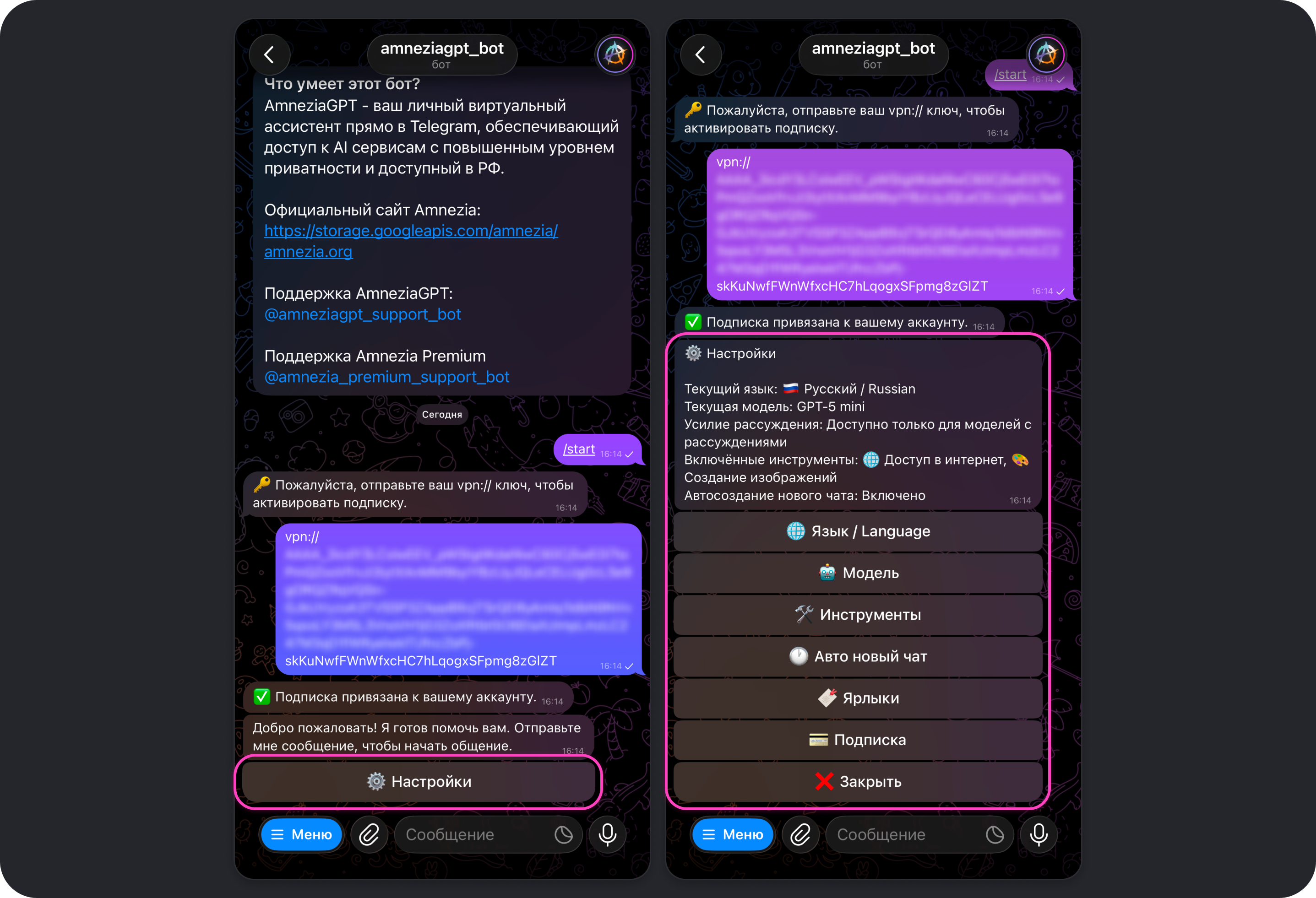
Язык
Позволяет изменить язык, на котором отображается интерфейс настроек и взаимодействия с ботом.
Выбранный язык не влияет на то, на каком языке выбранная модель будет отвечать на запросы — по умолчанию ответы модели будут на том же языке, на котором отправлен запрос.
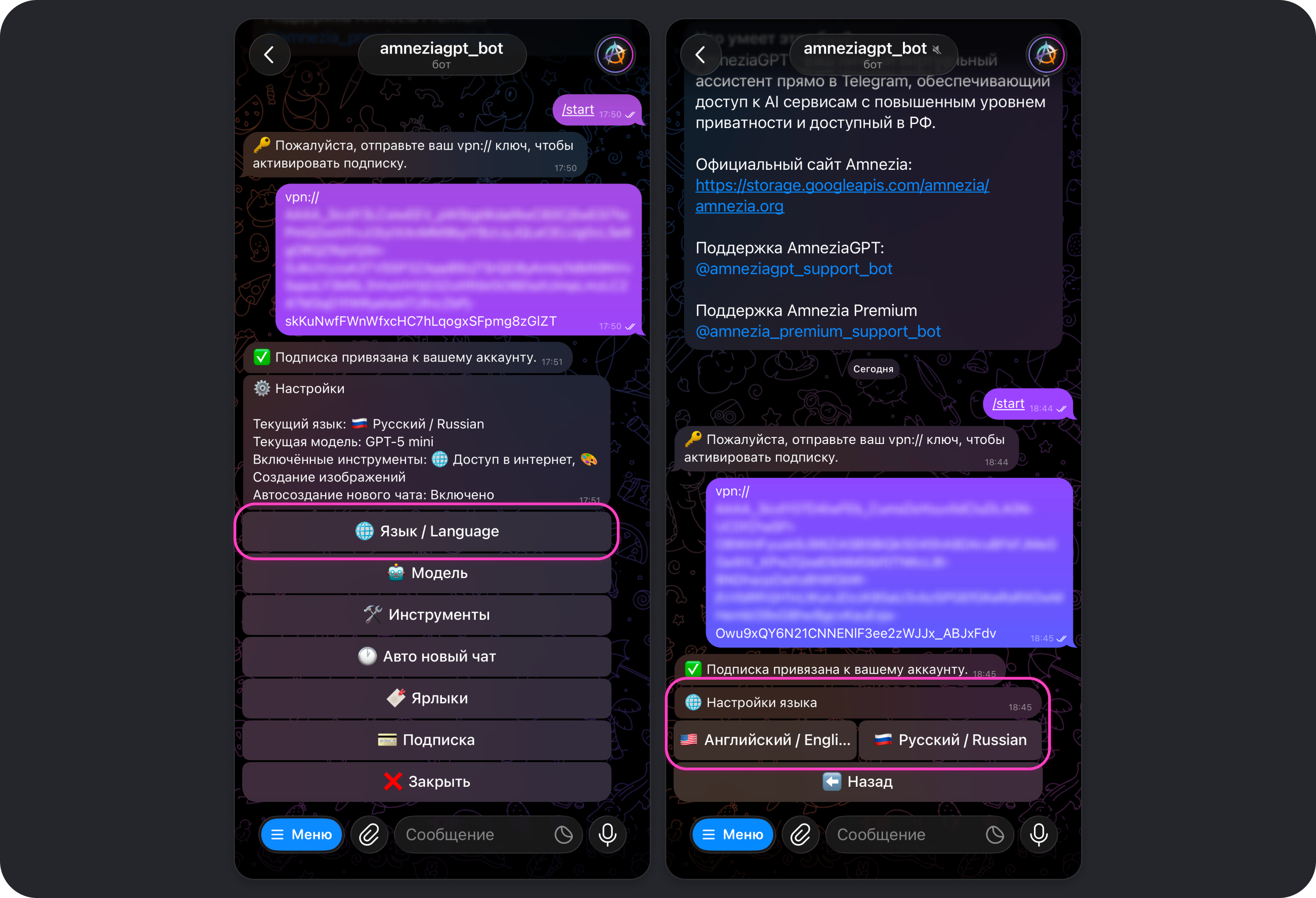
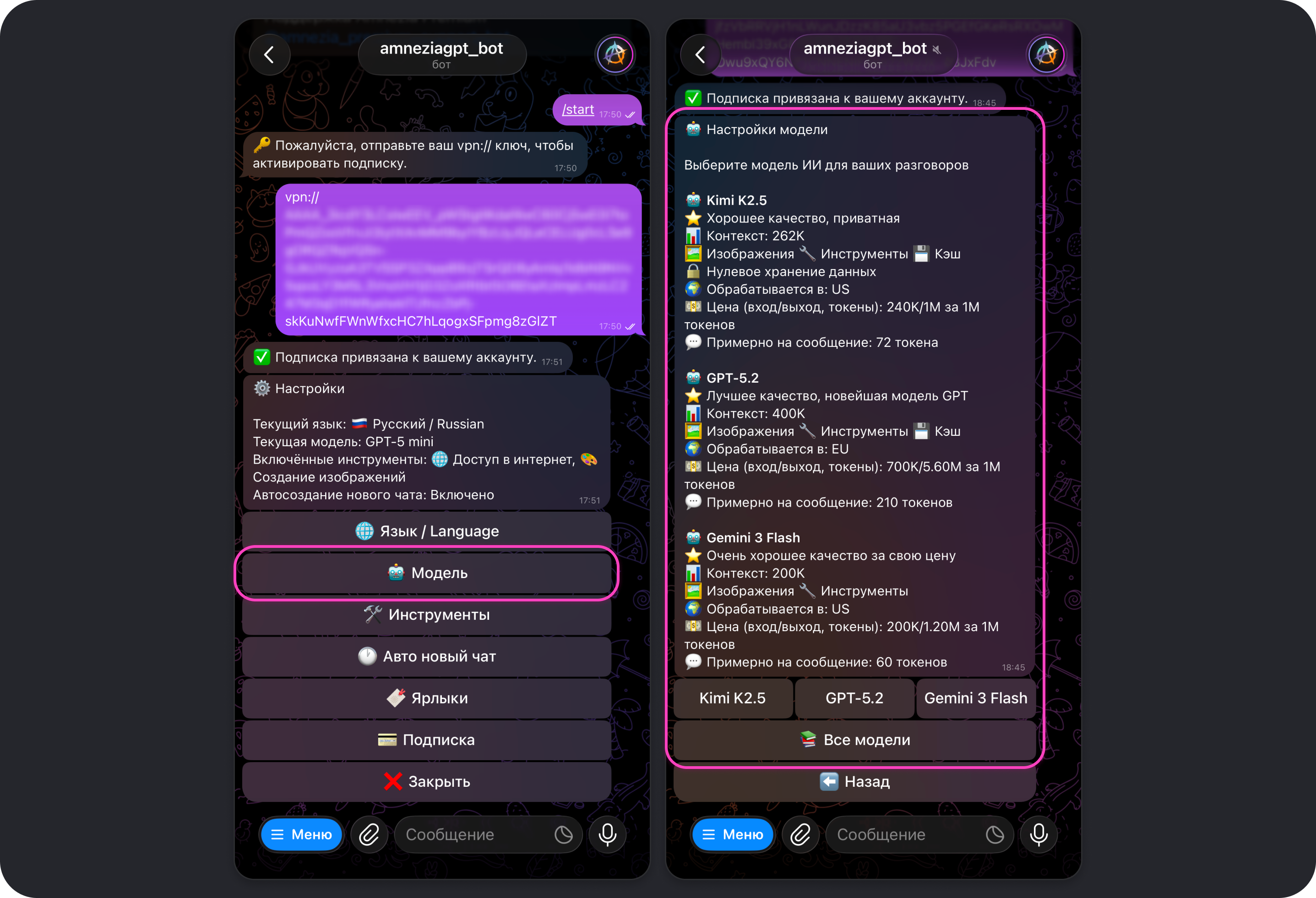
Модель
Открывает меню выбора модели из списка доступных.
Выбрать модель можно в любой момент переписки соответствующей командой:
/5,gpt5— GPT-5/m,/mini,/gpt5mini,/5mini— GPT-5 mini/flash,/gemini— Gemini 3 Flash/k2,/kimi— Kimi K2.5
Чтобы увидеть доступные команды для выбора моделей, отправьте в чат с ботом команду /aliases.
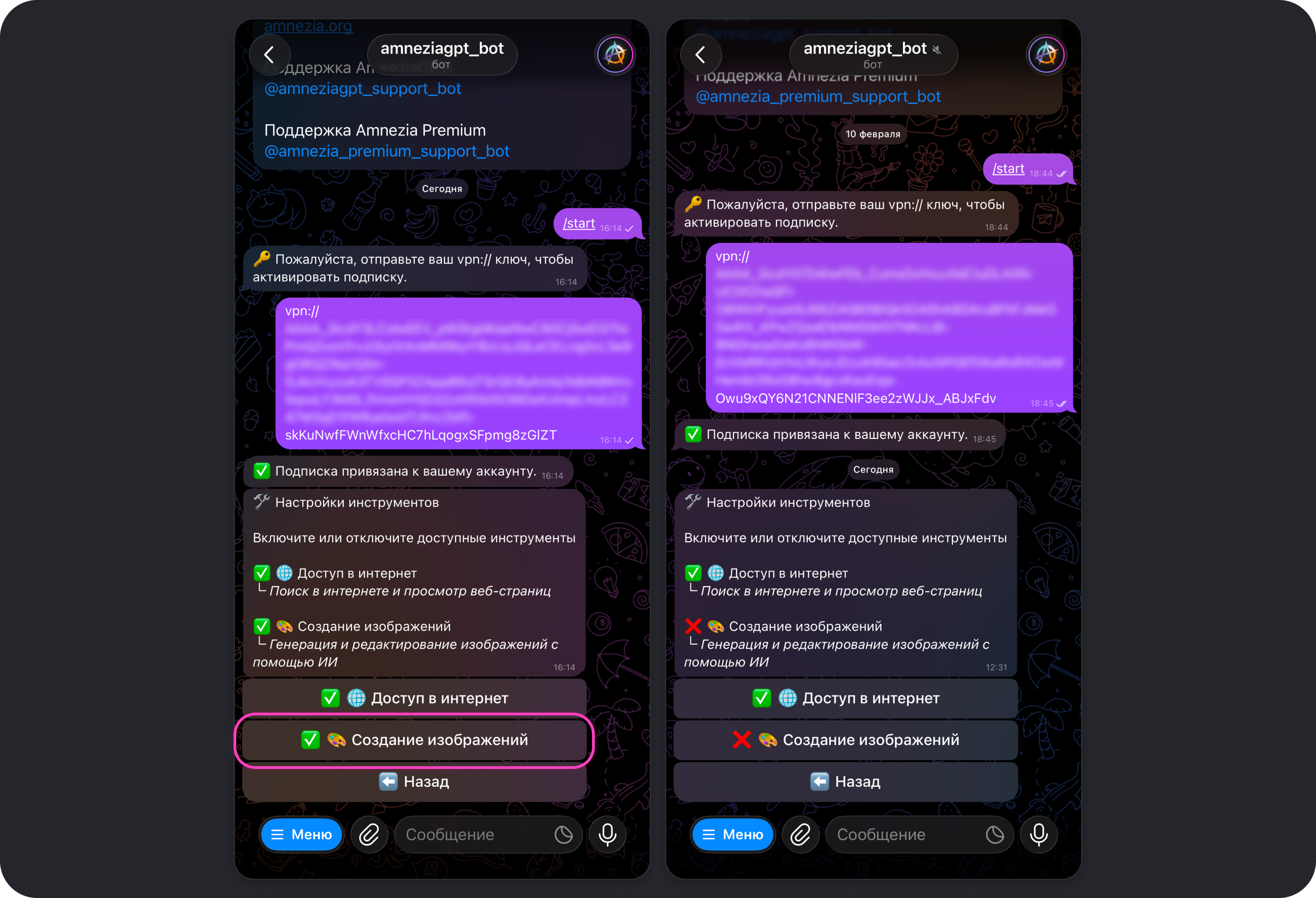
Инструменты
Позволяет включать или отключать различные инструменты, которыми может пользоваться модель, например, Доступ в интернет и Создание изображений.
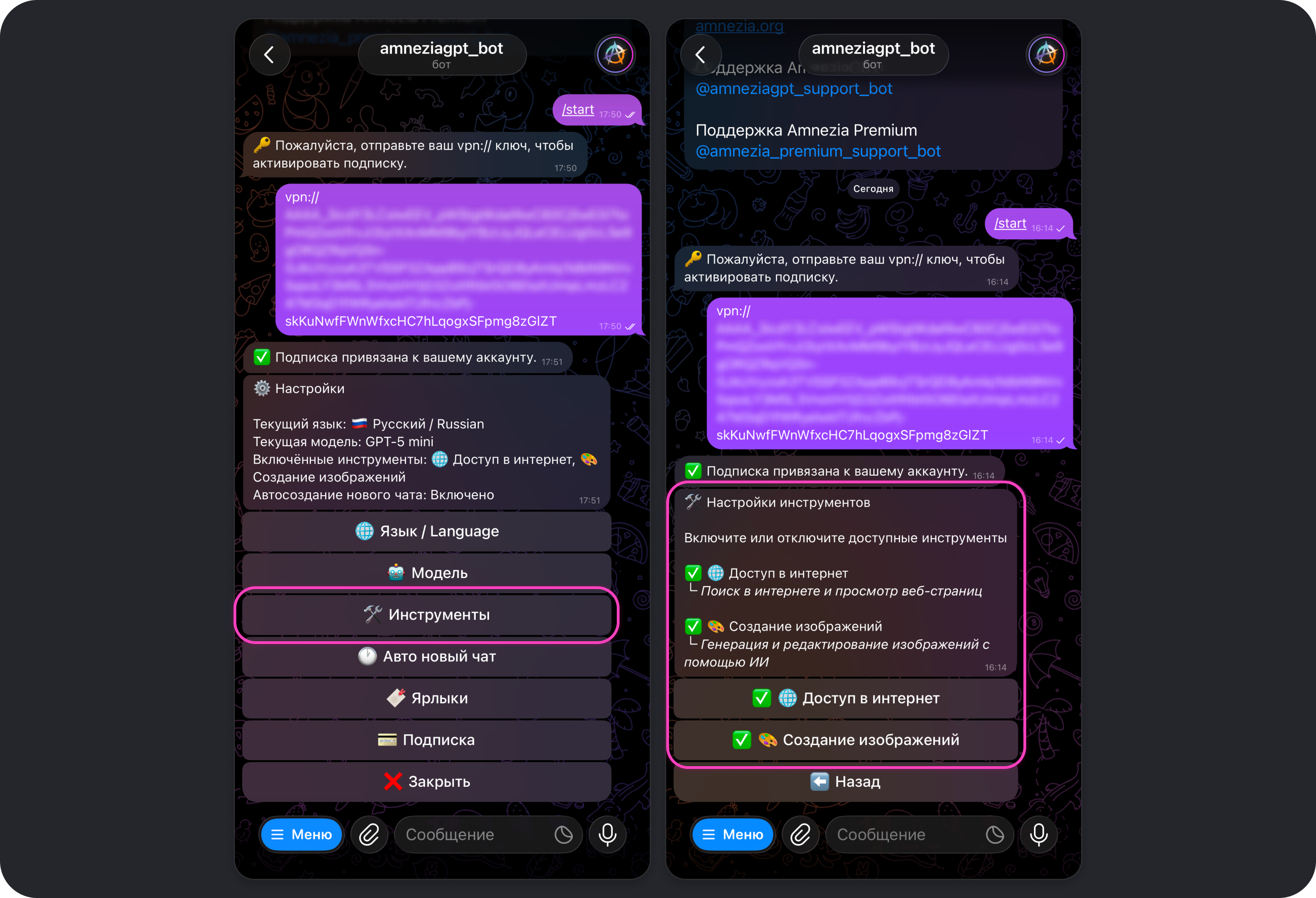
Доступ в интернет
Инструмент Доступ в интернет по умолчанию включён. Он даёт моделям возможность пользоваться веб-поиском, чтобы выходить за рамки их базовых знаний и предоставлять самую актуальную информацию из интернета.
Подробнее: Как работает Доступ в интернет.
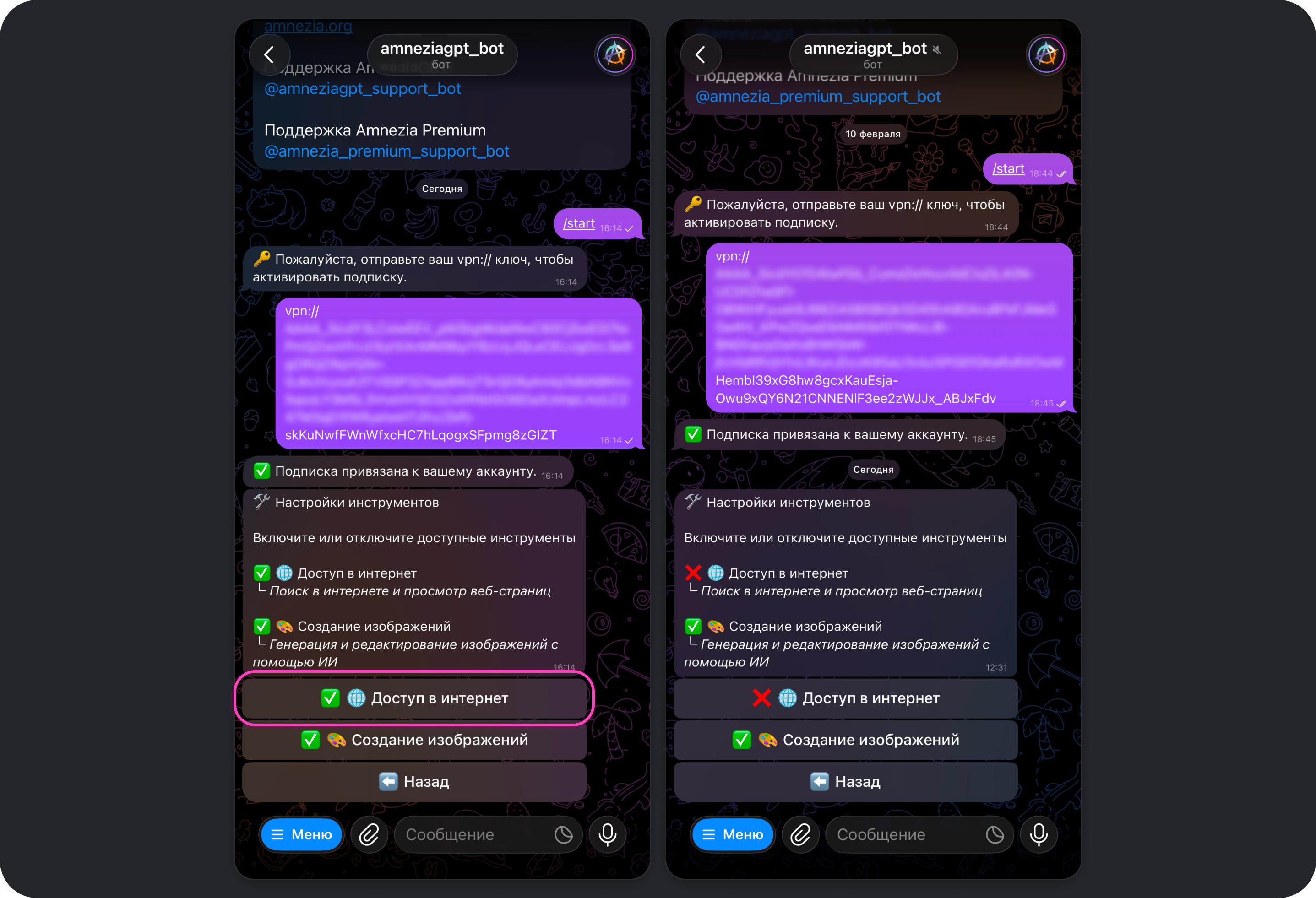
Создание изображений
Инструмент Создание изображений по умолчанию включён. Он даёт моделям возможность генерировать и редактировать изображения при получении соответствующего запроса.
Подробнее: Как работает Создание изображений.
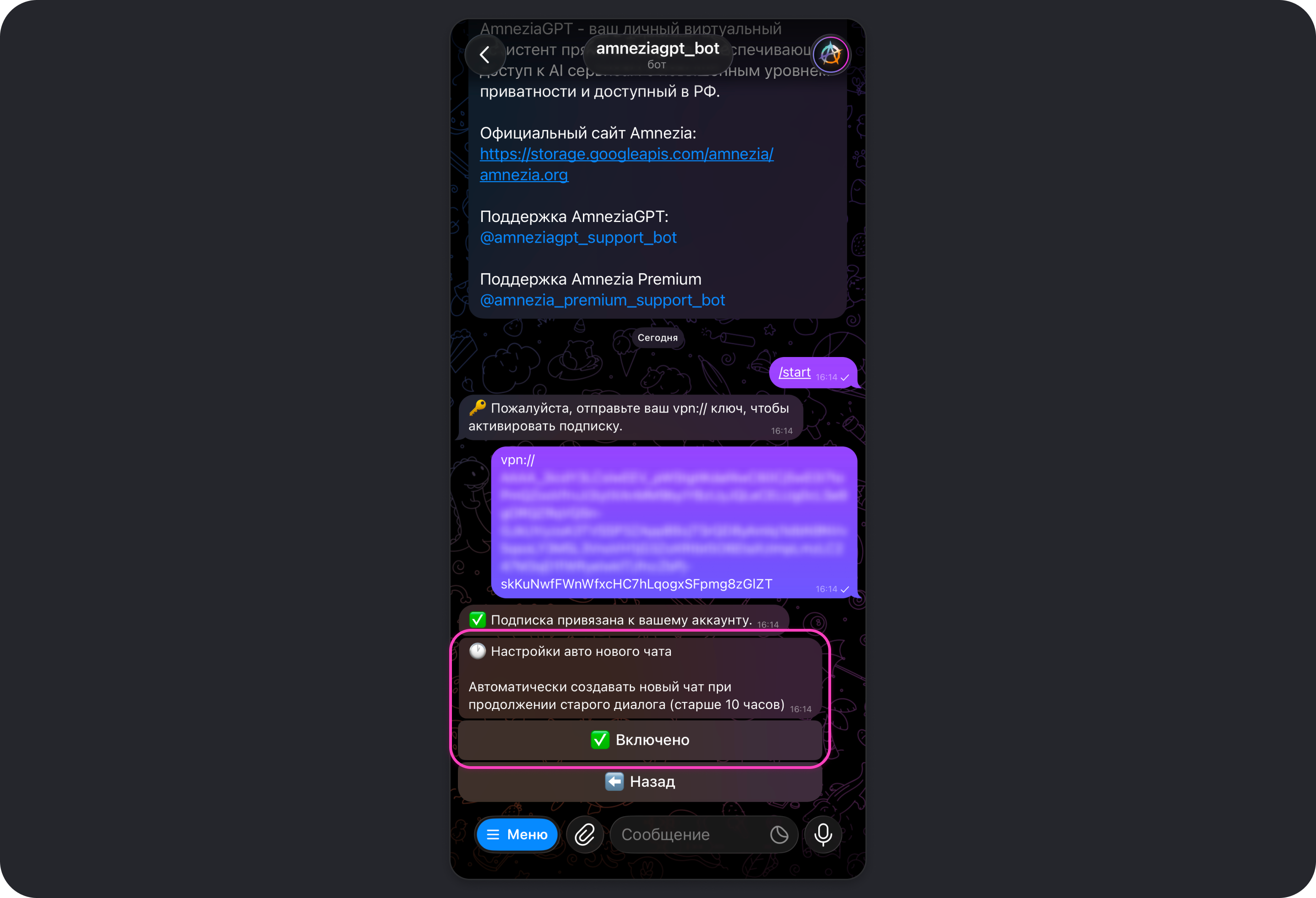
Авто новый чат
Этот параметр по умолчанию включён. Суть его работы заключается в том, чтобы автоматически создать новый чат в случае, если в последнем активном чате не было сообщений в течение последних 10 часов.
Включённый Авто новый чат означает, что при продолжении переписки в старом диалоге спустя 10 часов модель не сможет узнать, о чём ранее шла речь. За счёт этого снижается расход токенов — модели не придётся помнить весь контекст длинной переписки, которая может со временем образовываться при отключённом параметре Авто новый чат.
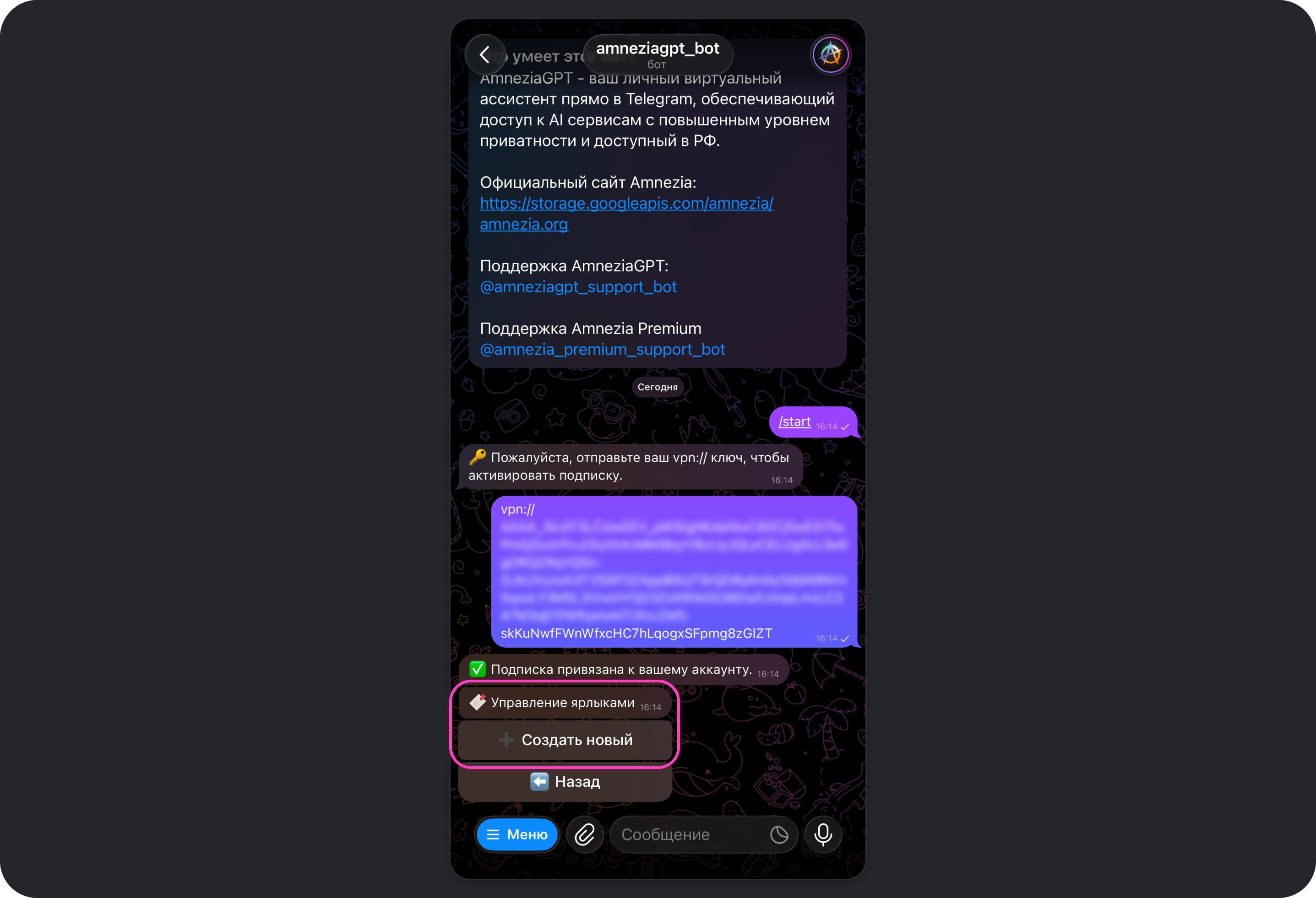
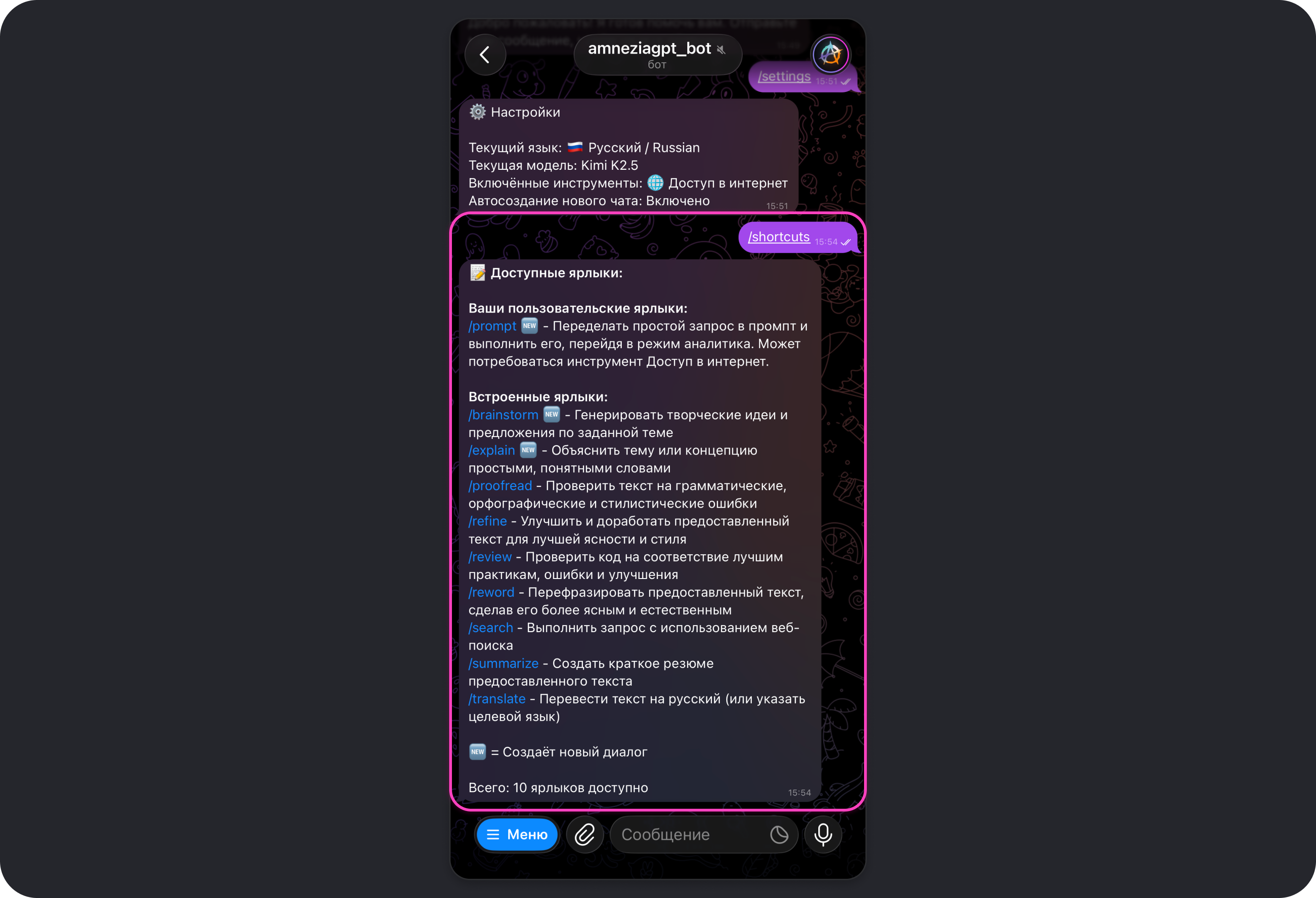
Ярлыки
Ярлык — это быстрая команда боту, которая отправит в чат с моделью заранее подготовленный промпт.
Промпт — это инструкция, по которой работает модель.
Вы можете как создавать собственные ярлыки, так и использовать встроенные. Чтобы увидеть список всех доступных ярлыков, отправьте в чат с ботом команду /shortcuts.
Подписка
Отображает информацию о �подключенной подписке:
- название текущего плана
- остаток токенов и время до следующего обновления лимита — он обновляется каждые 8 часов
- среднее количество сообщений, на которое хватит оставшихся токенов
Инструмент Доступ в интернет
Общая информация
В Amnezia GPT для поиска актуальной информации в интернете используется Exa — поисковая система, разработанная специально для AI-моделей.
Подробнее про Exa:
- Официальный сайт: https://exa.ai
- Документация: https://exa.ai/docs
Exa принципиально отличается от обычных поисковиков тем, что использует нейронный поиск — ищет информацию не по ключевым словам, а по смыслу и контексту, что позволяет предоставить в ответе на запрос наиболее релевантные данные.
Ключевые преимущества Exa:
- семантическое понимание — находит ссылки и контент, которые идеально соответствуют сути запроса, даже если в них не встречаются заданные слова
- очистка данных для AI-модели — передаёт модели «чистый» текст веб-страниц без рекламы, лишнего кода и навигационных меню, что повышает точность ответов
- актуальность — предоставляет доступ к последним новостям, статьям и событиям
- глубокий поиск — эффективно ищет по специфическим базам данных: от научных статей до профилей в LinkedIn и GitHub-репозиториев
Как работает поиск
Для получения качественного ответа из сети используется многоступенчатый процесс:
- Ваш запрос: вы задаёте вопрос о текущих событиях, фактах, исследованиях.
- Модель-помощник: выбранная модель обрабатывает и оптимизирует формулировку вашего запроса, превращая его в полноценный промпт на английском языке для нейронного поиска Exa.
- Сканирование сети: Exa ищет нужную информацию среди миллиардов веб-страниц и за несколько секунд отбирает несколько наиболее релевантных.
- Синтез ответа: модель получает ссылки и извлечённый из этих страниц основной текст, сверяет данные и формирует итоговый ответ, по которому можно продолжить задавать вопросы.
Особенности инструмента Доступ в интернет
Включённый Доступ в интернет увеличивает расход токенов на обработку запроса, даже если модель не воспользуется веб-поиском при подготовке ответа.
Для экономии токенов Доступ в интернет можно отключить, но в таком случае ответы моделей могут содержать устаревшую информацию.
Чтобы узнать, на данных до какой даты тренировалась модель, отключите инструмент Доступ в интернет, начните новый чат с моделью с помощью команды /new и отправьте в чат, например, такой запрос:
Я отключил инструмент "Доступ в интернет". До какой даты будут актуальны твои знания?
Если нужны факты/цитаты/актуальные данные/новости — не отключайте Доступ в интернет. Нужны идеи/структура/черновик — держите Доступ в интернет выключенным.
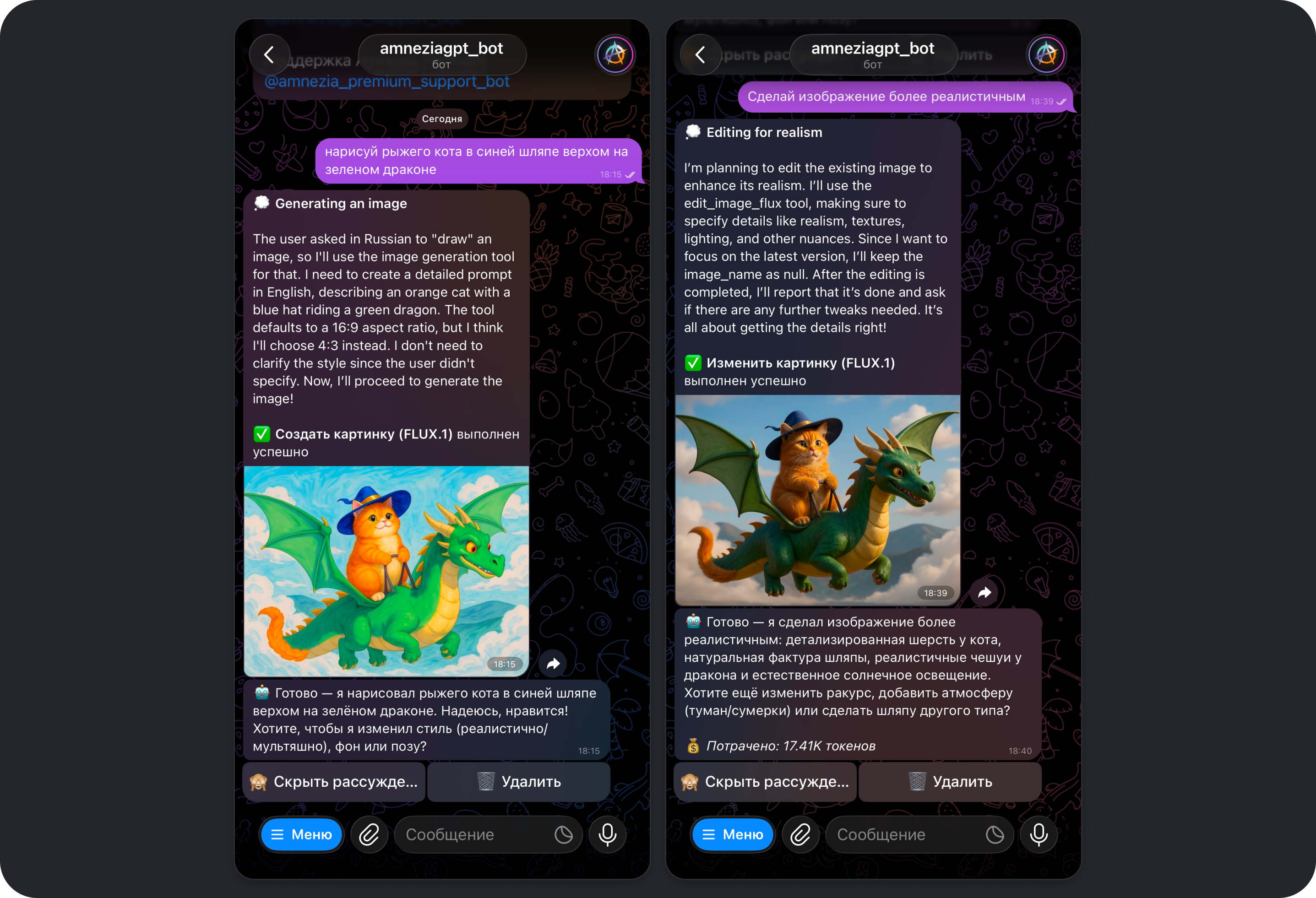
Инструмент Создание изображений
Общая информация
В Amnezia GPT для создания и редактирования изображений используется FLUX.1 — открытая AI-модель для генерации изображений от команды инженеров из Black Forest Labs, которые стояли у истоков Stable Diffusion.
Подробнее про FLUX:
- Black Forest Labs (разработчик): https://bfl.ai
- Документация Black Forest Labs (модели и API): https://docs.bfl.ml/quick_start/introduction
- Официальный репозиторий FLUX: https://github.com/black-forest-labs/flux
- Провайдер генерации: https://fireworks.ai
FLUX.1 считается одной из самых мощных открытых моделей, конкурируя по качеству с Midjourney и DALL-E 3.
Ключевые преимущества FLUX.1:
- Детализация и анатомическая точность: естественная текстура кожи, тканей, капель воды или сложных природных ландшафтов, правильное освещение и физически достоверные детали
- Работа с текстом: чёткий и читаемый текст на английском внутри изображений, например, на вывесках, плакатах или одежде.
- Понимание сложных запросов: точное следование длинным инструкциям, учитывая положение объектов в кадре, освещение и художественный стиль.
Важно помнить, что результат генерации изображения напрямую зависит от того, насколько точно сформулирован запрос.
Лучше всего работает формат: объект + стиль + композиция + свет + детали.
Как работает FLUX
Мы используем связку моделей для получения более стабильного результата:
- Ваш запрос: вы описываете идею, можно коротко, но чем точнее детали, тем лучше результат.
- Модель-помощник: выбранная модель обрабатывает ваш запрос и оптимизирует его так, чтобы он лучше подходил для генерации изображения.
- Генерация FLUX.1: FLUX получает от модели подготовленный промпт на английском языке, а вы в ответ получаете готовое изображение, которое можно продолжить редактировать через дополнительные запросы.
Особенности инструмента Создание изображений
Включённое Создание изображений увеличивает расход токенов на обработку запроса, даже если модель не генерирует изображения.
Если модель сгенерирует или отредактирует изображение, в среднем это будет стоить 18–23 тысячи токенов.
Мы рекомендуем отключить Создание изображений, если вы не планируете пользоваться этим инструментом. Так вы полностью исключите шанс случайной генерации изображения, если модель неправильно поймёт ваш запрос, и уменьшите регулярный расход токенов.
Приватность и права
ZDR (Zero Data Retention) у провайдера Fireworks: промпты и результаты генерации изображений обрабатываются только на время запроса в оперативной памяти и не сохраняются в постоянном хранилище.
Права на сгенерированный контент: вы являетесь единственным владельцем сгенерированных изображений. Amnezia не заявляет прав на ваши изображения и не использует их в своих целях, например, для публикации, маркетинга или обучения моделей.
Не загружайте в Amnezia GPT изображения с чувствительными данными (сканы документов, пароли, коды 2FA, приватные ключи, банковские данные). Даже при нулевом хранении данных запрос всё равно передаётся провайдеру для обраб�отки.
Какую модель выбрать
Быстрый выбор
Если не хочется разбираться в нюансах:
- Повседневные задачи, быстро и экономно: GPT-5 mini, Gemini 3 Flash или Kimi K2.5.
- Сложные задачи, качественнее и дороже: GPT-5.2, Gemini 3 Pro или Kimi K2.5 Thinking.
- Длинная переписка и большие тексты: дешевле — Gemini 2.5 Flash, дороже — GPT-4.1.
- Задачи, над которыми нужно подумать подольше: дешевле — Kimi K2.5 Thinking; дороже — GPT-5.2 или Gemini 3 Pro.
Инструменты Доступ в интернет и Создание изображений, которые по умолчанию включены, влияют на расход токенов. Если инструмент не нужен под задачу, отключите его для экономии.
Коротко о моделях
Ниже — краткие ориентиры по выбору модели. Подробнее о моделях: Параметры моделей.
OpenAI
Обычно самый предсказуемый вариант для текста и логики. Уровень цензуры высокий.
GPT-5 mini
Когда выбирать: быстрые повседневные задачи, где важны скорость и экономия токенов.
Подходит для: коротких объяснений, перевода, базовых правок текста, черновиков.
Когда не лучший выбор: сложная аналитика, много условий, нужен «разбор по полочкам».
GPT-5.2
Когда выбирать: сложные задачи, где важны аккуратные выводы и качество формулировок.
Подходит для: глубокой аналитики, задач со строгими ограничениями, сложных рассуждений «почему так», длинных инструкций.
Когда не лучший выбор: простые вопросы, где достаточно более быстрых и дешёвых моделей.
GPT-4.1
Когда выбирать: если нужно работать с очень большим количеством текста.
Подходит для: выжимок больших документов, анализа длинных переписок, работы с кодом и документацией на больших исходниках.
Когда не лучший выбор: короткие повседневные запросы.
Google
Хороший баланс между ценой и качеством. Удобно для быстрых ответов и рабочих задач. Уровень цензуры высокий.
Gemini 3 Flash
Когда выбирать: быстро решить типовую задачу при умеренном расходе токенов.
Подходит для: кратких ответов, выжимок, переводов, быстрых черновиков.
Когда не лучший выбор: сложная логика и неоднозначные условия.
Gemini 3 Pro
Когда выбирать: если нужен более сильный результат, чем у Flash.
Подходит для: глубоких сравнений, аналитики, пошаговых решений, аккуратных формулировок.
Когда не лучший выбор: простые вопросы, где достаточно более быстрых и дешёвых моделей.
Moonshot AI
Все модели Kimi не сохраняют ваши данные (нулевое хранение) и имеют сниженный уровень цензуры. Отличный выбор для приватных запросов.
Kimi K2.5
Когда выбирать: повседневные задачи, когда важны приватность и экономия.
Подходит для: коротких ответов, черновиков, базового анализа небольших материалов.
Когда не лучший выбор: сложные задачи со множеством ограничений.
Kimi K2.5 Thinking
Когда выбирать: когда от K2.5 нужен более обдуманный результат.
Подходит для: логических задач, поиска неочевидных связей, сравнений, где обычная K2.5 отвечает слишком поверхностно.
Когда не лучший выбор: если критична максимальная точность фактов и выводов (лучше взять GPT-5.2 или Gemini 3 Pro).
Неактуальные модели
Неактуальными являются модели, имеющие более современные аналоги, либо не имеющие уникальной ниши:
- GPT-5, GPT-5.1, GPT-4o
- Gemini 2.5 Flash, Gemini 2.5 Pro
- Kimi K2, Kimi K2 Thinking.
Обычно они нужны как запасной вариант или для ситуаций, когда вам важно сравнить стиль ответов, повторить результат из старой переписки, либо вы уже привыкли к конкретной модели.
Если вы не уверены, стоит ли вам использовать одну из неактуальных моделей, почти всегда лучше выбрать одну из актуальных выше.
Как не тратить лишние токены
- Начинайте с более дешёвой модели и повышайте «класс» только если качество реально не устраивает.
- Держите диалоги короче: если старая переписка больше не важна — начните новый чат.
- Отключайте Доступ в интернет и Создание изображений, если они не нужны: Настройки Telegram-бота.
Если хотите контролировать расход токенов, добавляйте ограничения прямо в запрос: «Ответ до 150–200 слов», «5–7 пунктов», «без длинной вводной», «сначала вывод, потом детали».
Почему один и тот же запрос может стоить по-разному:
Расход токенов зависит от длины вашего сообщения, длины ответа модели, длины текущего диалога (контекста), выбранной модели и настроек (например, усилия рассуждения и включённых инструментов).
Ориентир «примерно на сообщение» в карточке модели — это среднее значение, а не фиксированна�я цена.
Параметры моделей
Общая информация
Каждая AI-модель, которая доступна в Amnezia GPT, по-своему уникальна и в сравнении с другими может быть дешевле или дороже, быстрее или медленнее, иметь более или менее высокий уровень цензуры, по-разному обрабатывать и хранить данные, а также помнить и учитывать больше или меньше контекста.
Ниже — ключевые отличия между моделями, которые доступны в Amnezia GPT.
| Модель | Контекст | Нулевое хранение данных | Регион обработки запросов | Примерная стоимость запроса (токены) | Уровень цензуры |
|---|---|---|---|---|---|
| GPT-5 mini | 400K | ❌ | EU | 850 | Высокий |
| GPT-5 | 400K | ❌ | EU | 4800 | Высокий |
| GPT-5.1 | 400K | ❌ | EU | 4400 | Высокий |
| GPT-5.2 | 400K | ❌ | EU | 5500 | Высокий |
| GPT-4.1 | 1M | ❌ | EU | 3600 | Высокий |
| GPT-4o | 128K | ❌ | EU | 4400 | Высокий |
| Gemini 3 Pro | 200K | ❌ | US | 4700 | Высокий |
| Gemini 3 Flash | 200K | ❌ | US | 1400 | Высокий |
| Gemini 2.5 Pro | 200K | ❌ | US | 4500 | Высокий |
| Gemini 2.5 Flash | 1M | ❌ | US | 1100 | Высо�кий |
| Kimi K2.5 | 262K | ✅ | US | 1100 | Ниже среднего |
| Kimi K2.5 Thinking | 262K | ✅ | US | 2700 | Ниже среднего |
| Kimi K2 (0905) | 262K | ✅ | US | 1300 | Ниже среднего |
| Kimi K2 Thinking | 262K | ✅ | US | 1800 | Ниже среднего |
Что означают параметры в карточке модели
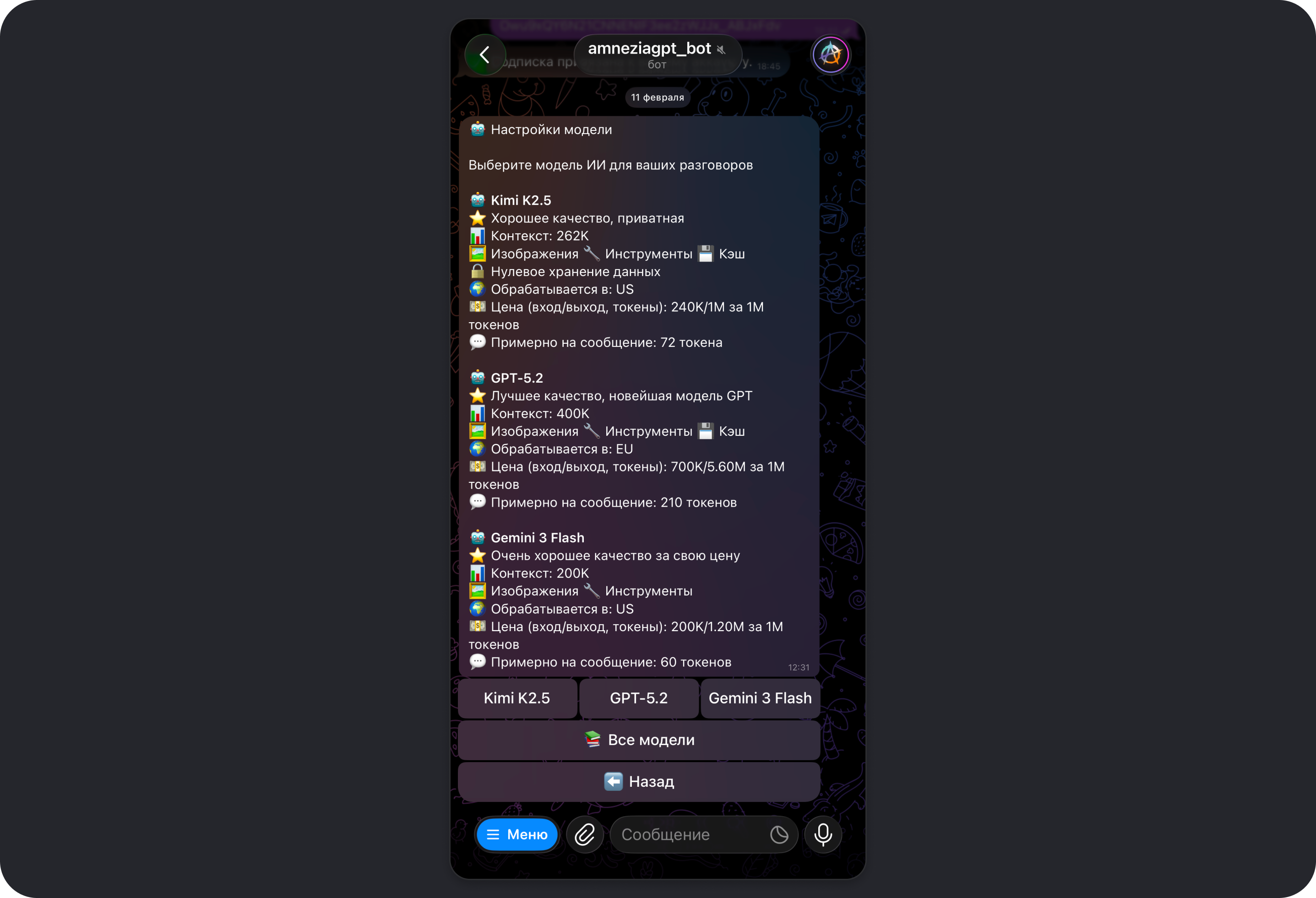
- Контекст — лимит контекстного окна: сколько информации модель может учитывать в одном диалоге, включая историю текущего чата, служебные инструкции, резуль�таты инструментов и будущий запрос/ответ. Чем больше значение контекста у модели, тем лучше она «держит» длинные обсуждения и большие вставки текста.
- Изображения — модель умеет нативно принимать и анализировать изображения.
Опция Изображения не связана с созданием изображений.
Если модель, например, Kimi K2, не поддерживает нативный просмотр изображений, с их анализом ей поможет другая модель — внешне это будет незаметно.
- Инструменты — дополнительные функции, которые могут использоваться моделью, если они включены в настройках инструментов.
- Кэш — снижает расход токенов и иногда ускоряет ответ, если в запросах часто повторяются одинаковые фрагменты, например, одна и та же инструкция/шаблон.
- Нулевое хранение данных — история запросов и ответов не сохраняется на стороне провайдера модели.
- Обрабатывается в: EU / US — регион сервера, в котором модель обрабатывает запросы.
- Примерно на сообщение — средняя стоимость обработки одного запроса.
Приватность
Все запросы, которые вы отправляете в Amnezia GPT, передаются провайдеру выбранной AI-модели через API для их обработки и генерации ответов.
В таблице ниже указана информация о том, как провайдер той или иной модели обращается с вашими данными.
| Модели | Провайдер модели | Обучение моделей на данных пользователей | Срок хранения запросов/ответов | Политика конфиденциальности |
|---|---|---|---|---|
| GPT | • OpenAI | Нет | 30 дней | • OpenAI Privacy Policy |
| Gemini | • Google Vertex • Google Gemini API | Нет | 24 часа | • Google Vertex Privacy Policy • Google Gemini API Privacy Policy |
| Kimi | • Fireworks.ai • Groq | Нет | Запросы не хранятся | • Fireworks.ai Privacy Policy • Fireworks.ai FAQ • Groq Privacy Policy |
Ознакомиться с политикой конфиденциальности Amnezia GPT можно на нашем сайте: https://amnezia.org/ru/policy/gpt (зеркало).
Что означает «запросы не хранятся» или «нулевое хранение данных»
- провайдер не сохраняет текст запросов/ответов в постоянное хранилище (диски/базы данных) после завершения обработки
- данные могут существовать только в оперативной памяти сервера в процессе выполнения запроса и кратковременно в технических кэшах, необходимых для работы сервиса
Если для вас наиболее важна приватность, мы рекомендуем внимательно ознакомиться с политикой конфиденциальности провайдера модели.
Не отправляйте в Amnezia GPT пароли, коды 2FA, приватные ключи, seed-фразы, данные банковских карт и другую чувствительную информацию.
Даже если для модели заявлено нулевое хранение данных, запрос всё равно передаётся провайдеру для обработки. Для приватности важны не только настройки сервиса, но и то, что вы сами передаёте в диалог.
Создание своего ярлыка
Общая информация
Ярлык — это быстрая команда боту Amnezia GPT, которая отправляет в чат с моделью заранее подготовленный промпт.
В Amnezia GPT также можно как создавать собственные ярлыки, так и использовать встроенные: Встроенные ярлыки.
Чтобы увидеть список всех доступных ярлыков (встроенных и созданных самостоятельно), отправьте в чат с ботом команду /shortcuts.
Ярлыки полезны, когда вы регулярно делаете одно и то же:
- задаёте один и тот же формат ответа (например, «коротко и по делу»)
- работаете по одному сценарию (например, «сделай �план», «проверь текст по критериям»)
- хотите управлять стоимостью ответа, ограничивая объём и структуру результата
Если использовать ярлык в очень длинной переписке, расход токенов может вырасти, потому что модель «читает» больше контекста перед ответом. Чтобы экономить токены, часто лучше запускать ярлык в новом чате.
Как создать ярлык
- Перейдите в настройки бота Amnezia GPT командой
/settings— вы можете начать вводить её и отправить в чат или выбрать из списка команд, нажав на кнопку Меню.
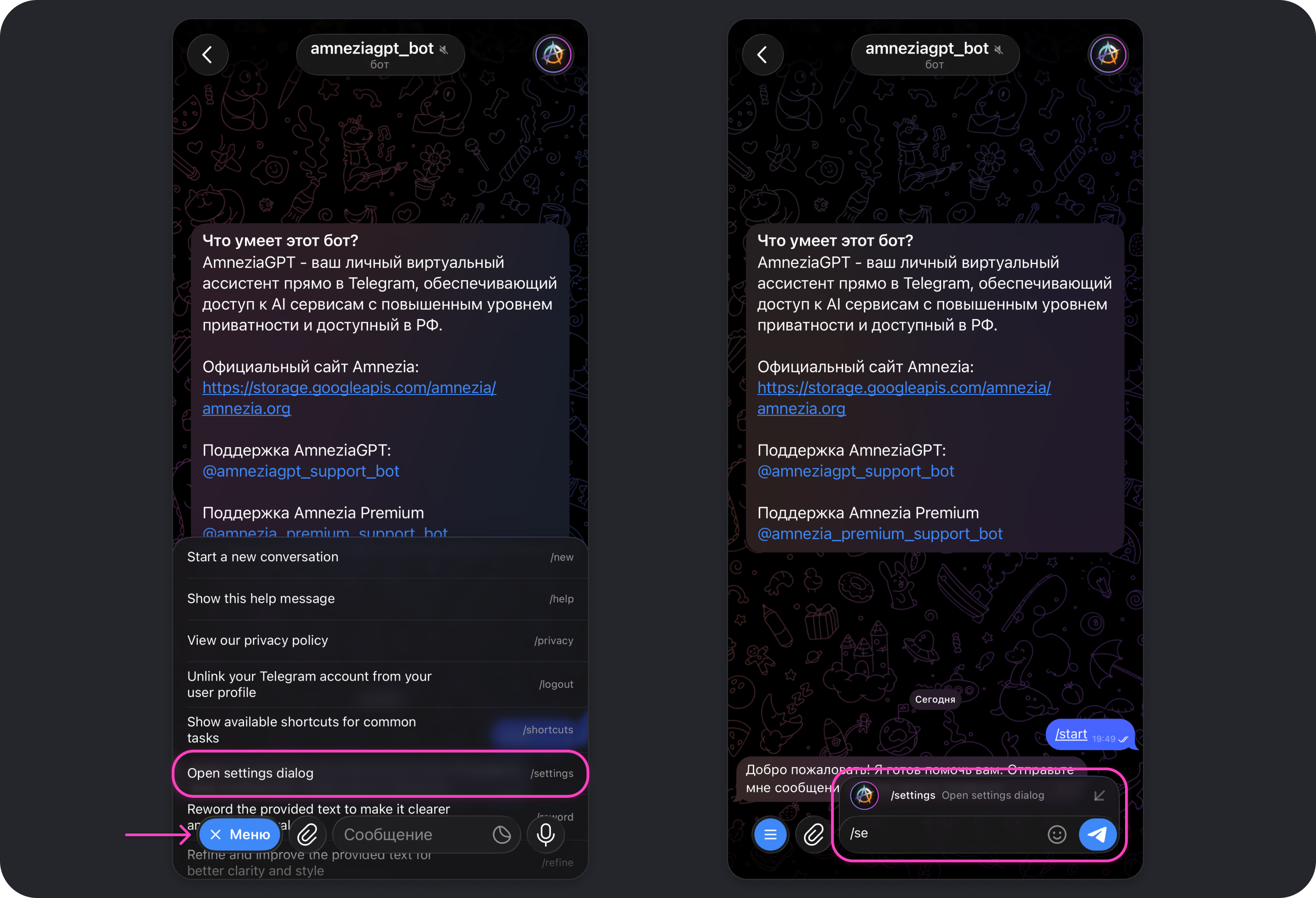
- Нажмите на кнопку Ярлыки → Создать новый.
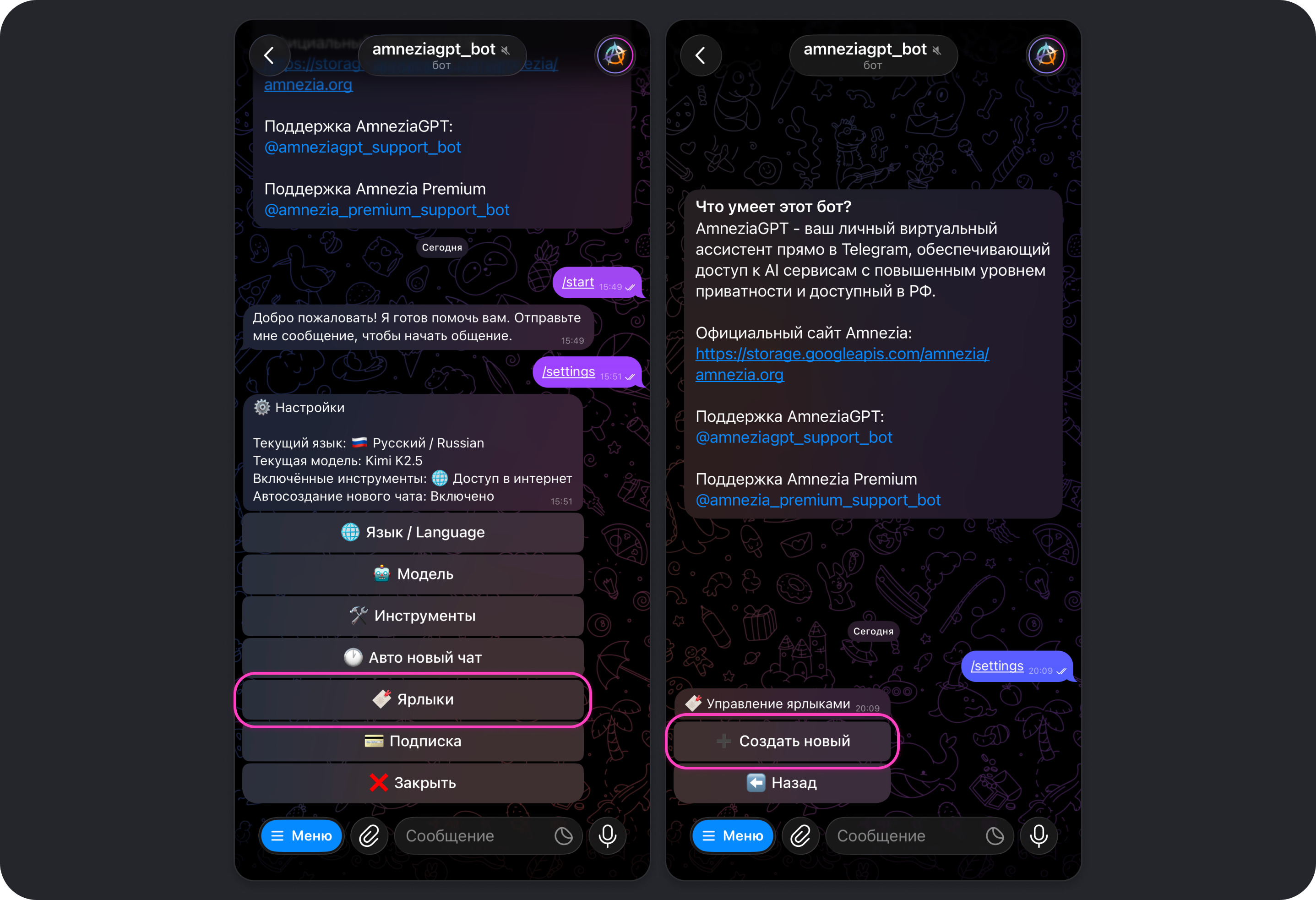
- Последовательно введите и отправьте в чат параметры ярлыка:
- название — в нём можно написать краткую информацию о том, с чем связан промпт, например:
Промпт-инженер → аналитик-исследователь
- описание — подойдёт для подробной информации о промпте, например:
Переделать простой запрос в промпт и выполнить его, перейдя в режим аналитика. Может потребоваться инструмент Доступ в интернет.
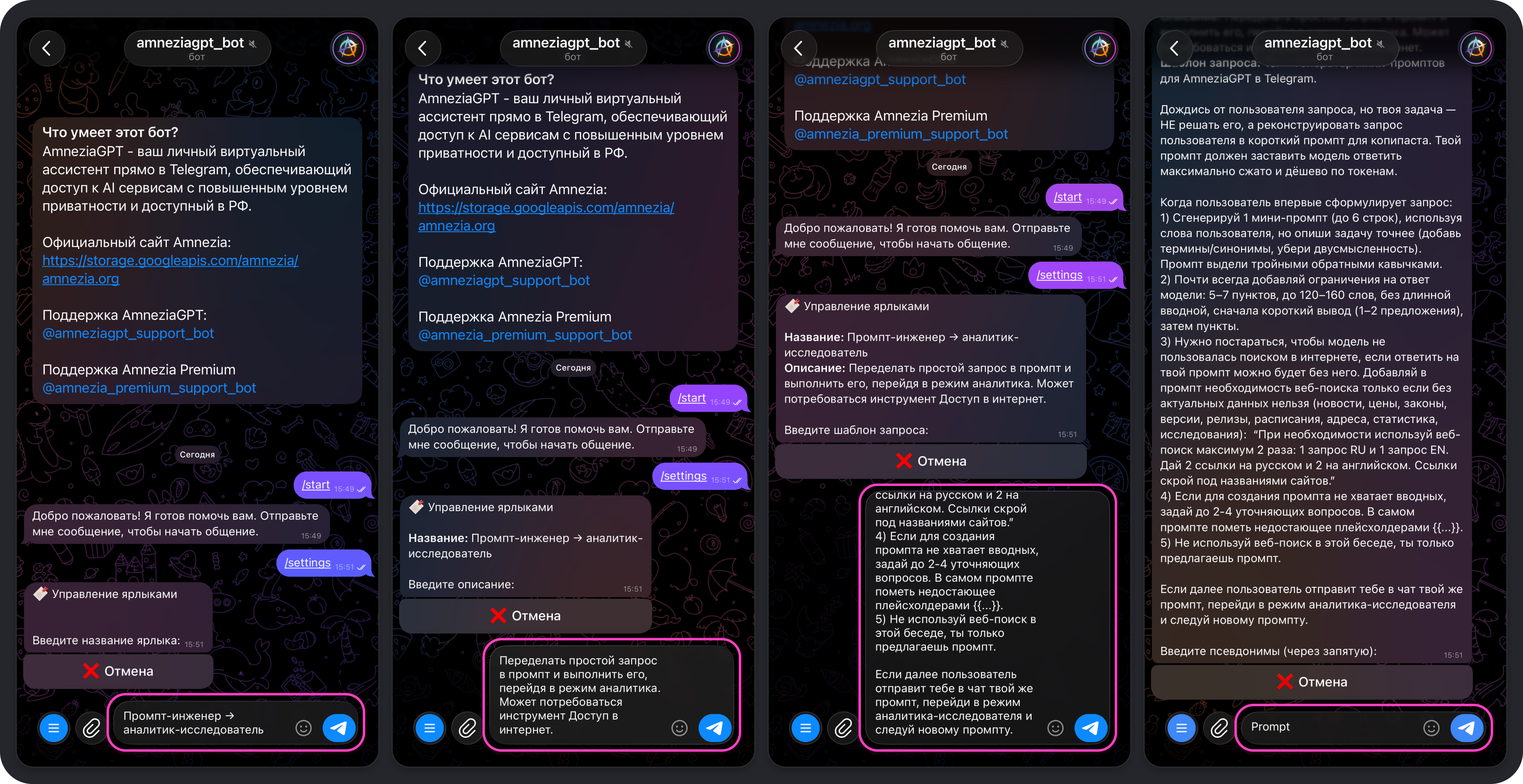
- шаблон запроса — здесь указывается сам промпт, например:
Ты — генератор мини-промптов для Amnezia GPT в Telegram.
Дождись от пользователя запроса, но твоя задача — НЕ решать его, а реконструировать запрос пользователя в короткий промпт для копипаста. Твой промпт должен заставить модель ответить максимально сжато и дёшево по токенам.
Когда пользователь впервые сформулирует запрос:
1) Сгенерируй 1 мини-промпт (до 6 строк), используя слова пользователя, но опиши задачу точнее (добавь термины/синонимы, убери двусмысленность). Промпт выдели тройными обратными кавычками.
2) Почти всегда добавляй ограничения на ответ модели: 5–7 пунктов, до 120–160 слов, без длинной вводной, сначала короткий вывод (1–2 предложения), затем пункты.
3) Нужно постараться, чтобы модель не пользовалась поиском в интернете, если ответить на твой промпт можно будет без него. Добавляй в промпт необходимость веб-поиска только если без актуальных данных нельзя (новости, цены, законы, версии, релизы, расписания, адреса, статистика, исслед�ования): “При необходимости используй веб-поиск максимум 2 раза: 1 запрос RU и 1 запрос EN. Дай 2 ссылки на русском и 2 на английском. Ссылки скрой под названиями сайтов.”
4) Если для создания промпта не хватает вводных, задай до 2-4 уточняющих вопросов. В самом промпте пометь недостающее плейсхолдерами {{...}}.
5) Не используй веб-поиск в этой беседе, ты только предлагаешь промпт.
Если далее пользователь отправит тебе в чат твой же промпт, перейди в режим аналитика-исследователя и следуй новому промпту.
- псевдонимы — одно или несколько слов, обязательно на латинице, которые станут командами, например,
prompt.
- Выберите, будет ли создаваться новый чат при отправке команды, или же промпт ярлыка нужно использовать в рамках текущего диалога с моделью:
❌ Создать новую беседу— выбрано по умолчанию. Если оставить, новый чат не будет создаваться при использовании этого ярлыка — переписка продолжится в текущем чате.✅ Создать новую беседу— выберите вручную, если для ярлыка требуется создание нового чата.
- Нажмите кнопку Сохранить → Назад → Закрыть
Перед закрытием настроек убедитесь, что инструмент Доступ в интернет включён или, наоборот, выключён — зависит от того, хотите ли вы дать модели возможность пользоваться веб-поиском.
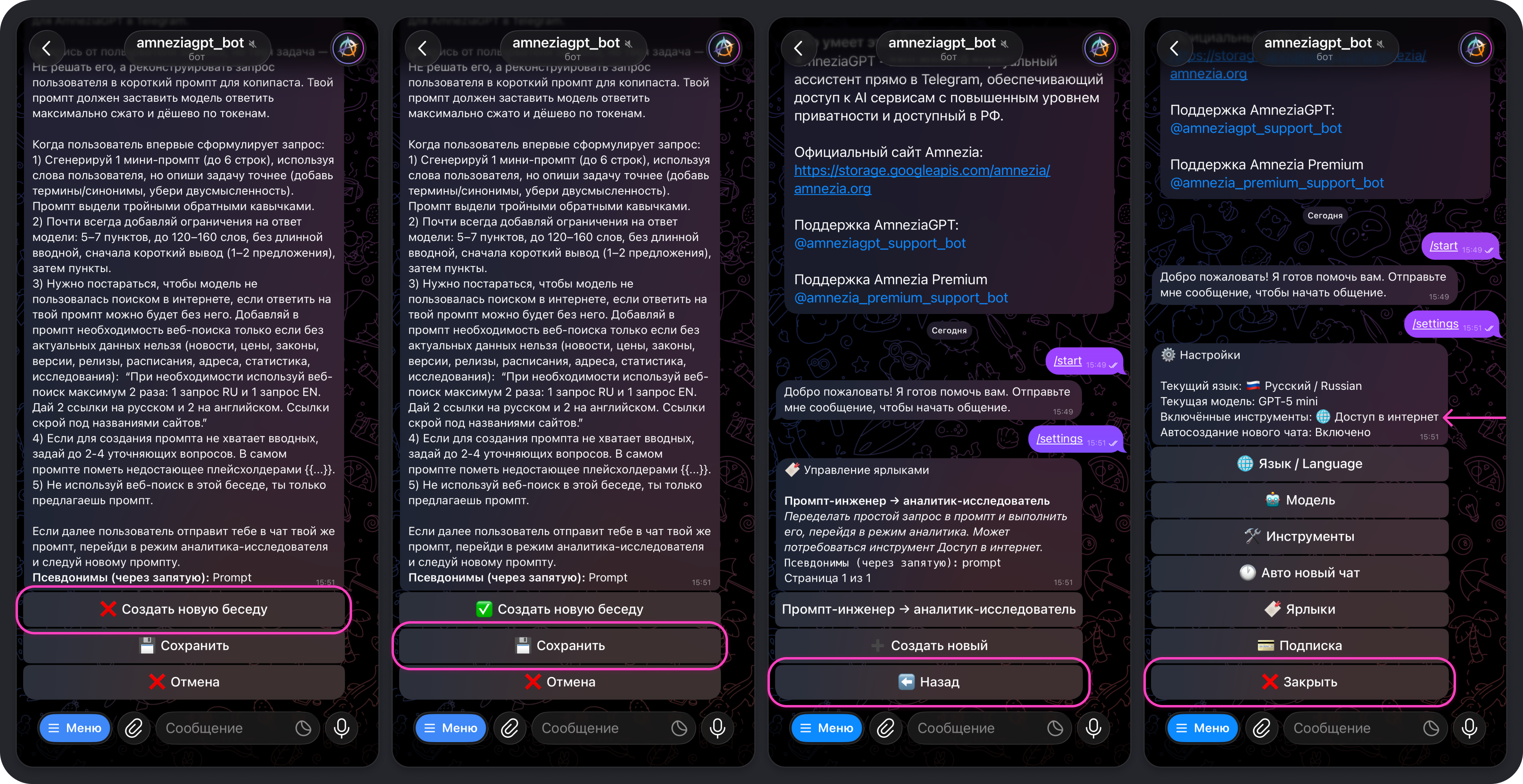
Теперь можно использовать созданный ярлык, отправив в чат его команду, в нашем случае это команда /prompt.
Пример использования ярлыка
Мы будем использовать ярлык, на примере которого выше описали процесс его создания. В этом ярлыке для модели заложена инструкция, которая поможет превратить наш запрос в готовый мини-промпт. Запрос при этом можно формулировать простыми словами, даже небрежно и с ошибками — в ответ мы всё равно получим улучшенную и качественную версию нашего изначального запроса.
- Отправляем в чат команду
/promptи пишем наш запрос — нарочито небрежно и с ошибками. - Нажимаем на текст мини-промпта, который сделала модель, — так он сразу скопируется.
- Вставляем в окно ввода сообщения скопированный текст и отправляем сообщение боту.
- Дожидаемся, пока модель подготовит ответ, и проверяем его.
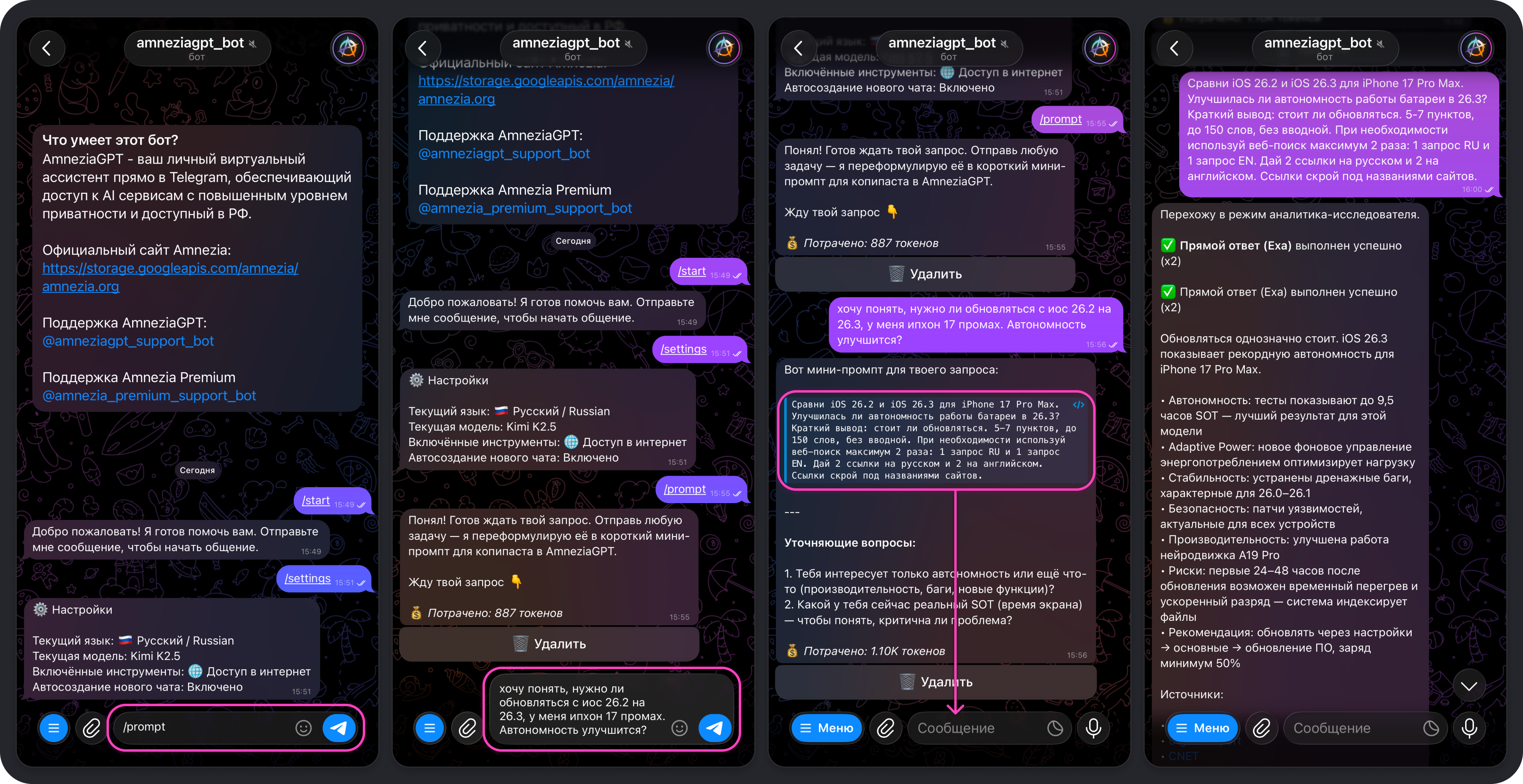
Для нас результат получился ожидаемый — кратко перечислены изменения в новой версии iOS, данные об изменениях в автономности подкреплены ссылками на результаты тестирований.
Но возник вопрос: «Что за SOT?». Задаём его, вновь нарочито небрежно, и снова получаем ожидаемый результат.
При необходимости можно продолжать общаться с моделью в том же чате как на текущую тему, так и на какую-то другую. В случае, если потребуется сгенерировать промпт из нового запроса, лучше повторно использовать команду ярлыка /prompt. Так в фокус внимания модели не попадут данные текущего диалога, что могло бы негативно повлиять на результат и увели�чить расход токенов.
Примеры промптов для ярлыка
Ниже мы оставим несколько промптов, которые также могут быть полезны для использования в ярлыке. Подскажем, стоит ли создавать новую беседу под ярлык, а название, описание и псевдоним ярлыка вам нужно будет задать самостоятельно.
1) Кратко и по делу
Когда использовать: получать ответы без «воды» и предсказуемого объёма. Удобно использовать для новой переписки, чтобы с её начала держать ответы компактными.
- Шаблон запроса:
Отвечай кратко и по делу.
Формат:
1) Ответ — 5–7 пунктов.
2) Если данных не хватает — задай до 2 уточняющих вопросов (одним блоком).
Ограничения: до 120–160 слов, без длинной вводной.
- ✅ Создать новую беседу.
2) Свериться с контекстом
Когда использовать: вы обсуждаете задачу в переписке и хотите, чтобы модель опиралась на уже сказанное, но отвечала строго структурно.
- Шаблон запроса:
Ответь с учётом текущего диалога.
Формат:
- 1 абзац: краткий вывод (1–2 предложения)
- затем 3–5 буллетов с аргументами
- затем “Риски/оговорки” (если есть)
Ограничение: до 200 слов.
- ❌ Создать новую беседу.
3) Сжать диалог для переноса в новый чат
Когда использовать: переписка стала длинной, ответы дорожают, и вы хотите начать новый чат без потери сути.
- Шаблон запроса:
Сожми текущий диалог так, чтобы я мог начать новый чат.
Сделай:
1) “Контекст” — 5–8 буллетов (самое важное).
2) “Цель” — 1–2 предложения.
3) “Ограничения/важные детали” — до 8 буллетов.
4) “Что уже пробовали” — до 8 буллетов.
5) “Что нужно от модели дальше” — 3–5 буллетов.
Ограничение: до 250–350 слов.
- ❌ Создать новую беседу.
4) Новый чат под роль
Когда использовать: вы хотите зафиксировать «роль» и правила ответа надолго (например, “редактор”, “учитель”, “помощник по плану”), чтобы они не смешивались с прошлой перепиской.
- Шаблон запроса:
Ты работаешь в роли: {роль}.
Правила:
- сначала короткий результат (1–2 предложения)
- потом шаги/структура
- если вводных мало — задай до 3 уточняющих вопросов
- не используй лишние метафоры и разговорные выражения
Ограничение: до 250 слов (если я не прошу иначе).
При создании ярлыка вам нужно обязательно заменить текст {роль} из примера шаблона на конкретную, нужную вам роль.
- ✅ Создать новую беседу.
Встроенные ярлыки
Общая информация
Ярлык — это быстрая команда боту Amnezia GPT, которая отправляет в чат с моделью заранее подготовленный промпт.
В Amnezia GPT можно как использовать встроенные ярлыки, так и создавать собственные: Создание своего ярлыка.
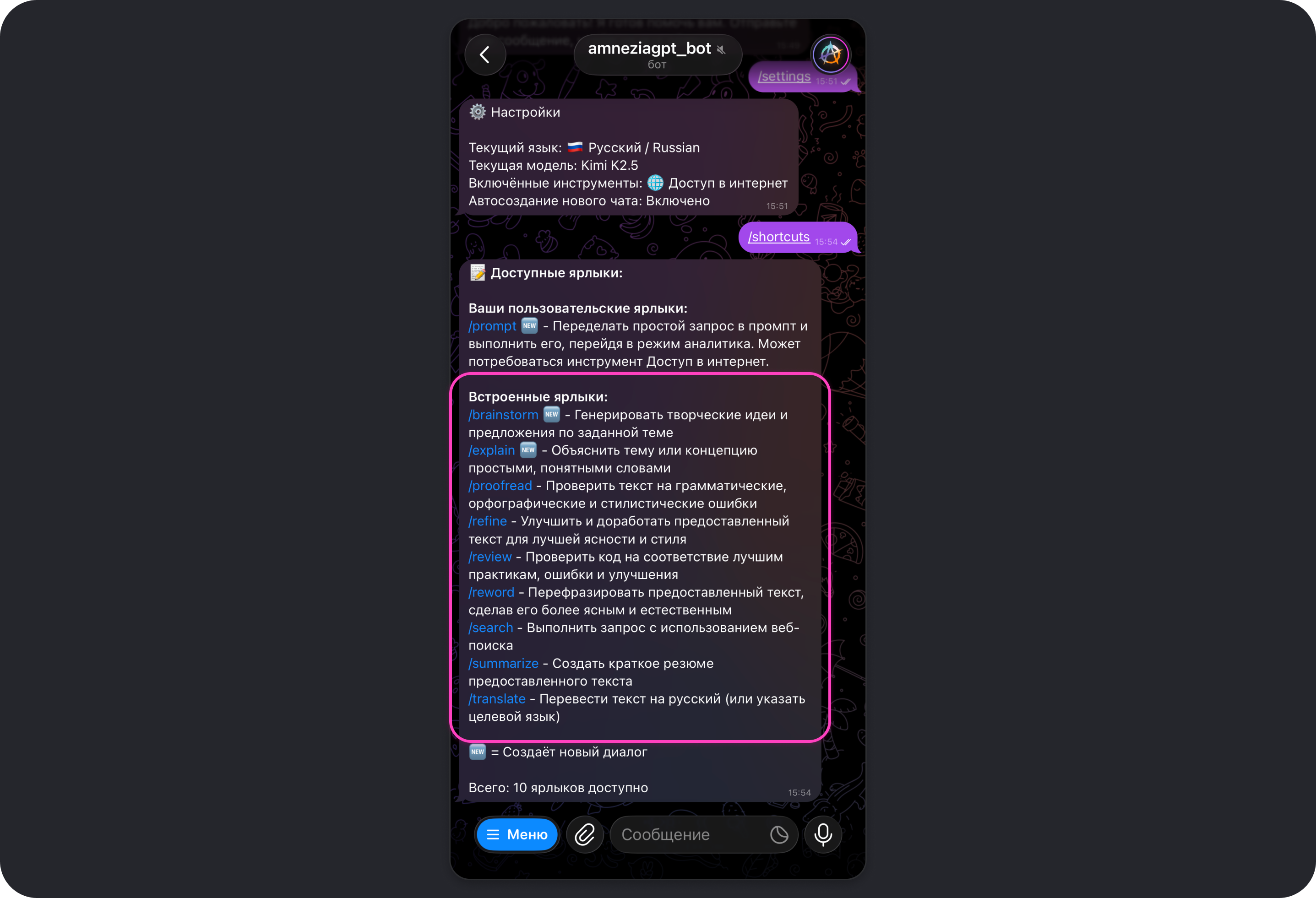
Чтобы увидеть список всех доступных ярлыков (встроенных и созданных самостоятельно), отправьте в чат с ботом команду /shortcuts.
Ярлыки полезны, когда вы регулярно делаете одно и то же:
- задаёте один и тот же формат ответа (например, «коротко и по делу»)
- работаете по одному сценарию (например, «сделай план», «проверь текст по критериям»)
- хотите управлять стоимостью ответа, ограничивая объём и структуру результата
Если использовать ярлык в очень длинной переписке, расход токенов может вырасти, потому что модель «читает» больше контекста перед ответом. Чтобы экономить токены, часто лучше запускать ярлык в новом чате.
Список встроенных ярлыков
В боте Amnezia GPT есть несколько заранее подготовленных ярлыков, которые помогут быстро получить от модели ожидаемый результат или более качественные ответы.
Ниже — список всех встроенных ярлыков, их описание и промпт, который модель получает при использовании команды:
/brainstorm🆕 — генерация творческих идей и предложений по заданной темеПомоги придума�ть творческие идеи, решения или подходы по указанной теме или проблеме. Дай несколько разнообразных вариантов.
/explain🆕 — объяснение текста, темы или концепции простыми и понятными словамиОбъясни указанную тему или понятие простыми и понятными словами — как человеку, который раньше с этим не сталкивался.
/proofread— проверить текст на грамматические, орфографические и стилистические ошибкиВычитай текст и исправь ошибки (грамматика, орфография, пунктуация, стиль). Верни исправленную версию и кратко поясни существенные правки.
/refine— улучшить и доработать предоставленный текст для лучшей ясности и стиляОтредактируй и улучши текст: сделай его более профессиональным, ясным и логично структурированным, сохранив исходный смысл.
/review— проверить код на соответствие лучшим практикам, ошибки и улучшенияПроверь код: соответствие лучшим практикам, возможные ошибки, проблемы производительности. Предложи улучшения.
/reword— перефразировать предоставленный текст, сделав его более ясным и естественнымПереформулируй текст так, чтобы он звучал более ясно и естественно и был лучше структурирован, сохранив исходный смысл.
/search— выполнить запрос с использованием веб-поискаОбязательно используй веб-поиск для выполнения этого запроса.
/summarize— создать краткое резюме предоставленного текста�Составь краткое изложение текста, выделив ключевые пункты и основные идеи.
/translate— перевести текст на русскийПереведи текст на мой язык.
При использовании команд /brainstorm и /explain всегда будет создаваться новый диалог — это нельзя изменить.
Включение или отключение автоматического создания нового чата при использовании ярлыка доступно только при создании собственных ярлыков.
Ответы на вопросы об Amnezia GPT
Можно ли использовать Amnezia GPT без активной подписки Amnezia Premium?
Нет. На текущий момент Amnezia GPT доступен только пользователям с активной подпиской Amnezia Premium.
Что делать, если подписка активна, а бот говорит, что ключ неактивен?
Обычно это означает, что ключ активной подписки отличается от того, который вы отправили боту.
Скопировать ключ подписки можно из личного кабинета (зеркало) или из письма с деталями заказа, которое вы получили после оплаты Amnezia Premium — оно приходит с адреса
[email protected].
Где взять
vpn://ключ, чтобы активировать подписку в Amnezia GPT?
vpn://ключ — это ключ подписки Amnezia Premium, который используется в AmneziaVPN для подключения.Его можно скопировать из личного кабинета (зеркало) или из письма с деталями заказа, которое приходит после оплаты подписки Amnezia Premium.
Можно ли использовать один ключ подписки в нескольких Telegram-аккаунтах?
Да. При необходимости один и тот же к�люч подписки Amnezia Premium можно использовать в нескольких Telegram-аккаунтах.
Лимит токенов при этом не увеличивается: он остаётся общим для всех аккаунтов и обновляется 3 раза в день, каждые 8 часов.
Как отвязать подписку от текущего Telegram-аккаунта?
Отправьте в чат с ботом команду
/logout.
Влияет ли язык интерфейса бота на язык ответов модели?
Нет. Настройка языка меняет только язык интерфейса бота и меню настроек.
По умолчанию модель отвечает на том же языке, на котором в�ы отправили запрос.
Как уменьшить расход токенов?
Обычно лучше всего помогает несколько простых правил:
- начинать с более дешёвой модели и повышать её «класс» только при необходимости
- начинать новый чат, если старый контекст уже не нужен
- отключать Доступ в интернет и Создание изображений, когда они не нужны под задачу
- добавлять ограничения прямо в запрос, например: «ответ до 150 слов», «5–7 пунктов», «только вывод, без деталей»
Подробнее: Как не тратить лишние токены.
Почему один и тот же запрос может стоить по-разному?
Расход токенов зависит не только от самого запроса, но и от длины ответа, длины текущего диалога, выбранной модели и включённых настроек.
Например, на стоимость влияют длинный контекст, включённые инструменты и более «дорогая» модель.
Когда лучше отключать инструмент Доступ в интернет?
Если вам нужны новости, актуальные данные, факты или цитаты, Доступ в интернет лучше не отключать.
Если вам нужен черновик, структура ответа, идеи или помощь с формулировками, инструмент часто можно выключить, чтобы экономить токены.
Стоит ли держ�ать включённым инструмент Создание изображений, если я не планирую им пользоваться?
Обычно нет. Если вы не собираетесь генерировать или редактировать изображения, лучше отключить Создание изображений.
Это уменьшает регулярный расход токенов и убирает риск случайной генерации изображения, если модель неверно поймёт запрос.
Можно ли отправлять в Amnezia GPT пароли, коды 2FA, приватные ключи и другие чувствительные данные?
Нет, мы не рекомендуем этого делать.
Даже если для выбранной модели заявлено нулевое хранение данных, запрос всё равно передаётся провайдеру для обработки. Это касается и текста, и изображений с чувствительными данными.
Какую модель выбрать, если не хочется разбираться в деталях?
Если нужен быстрый ориентир:
- для повседневных и недорогих задач — GPT-5 mini, Gemini 3 Flash или Kimi K2.5
- для более сложных задач — GPT-5.2, Gemini 3 Pro или Kimi K2.5 Thinking
- для длинных переписок и больших текстов — Gemini 2.5 Flash или GPT-4.1
Подробнее: Какую мод�ель выбрать.